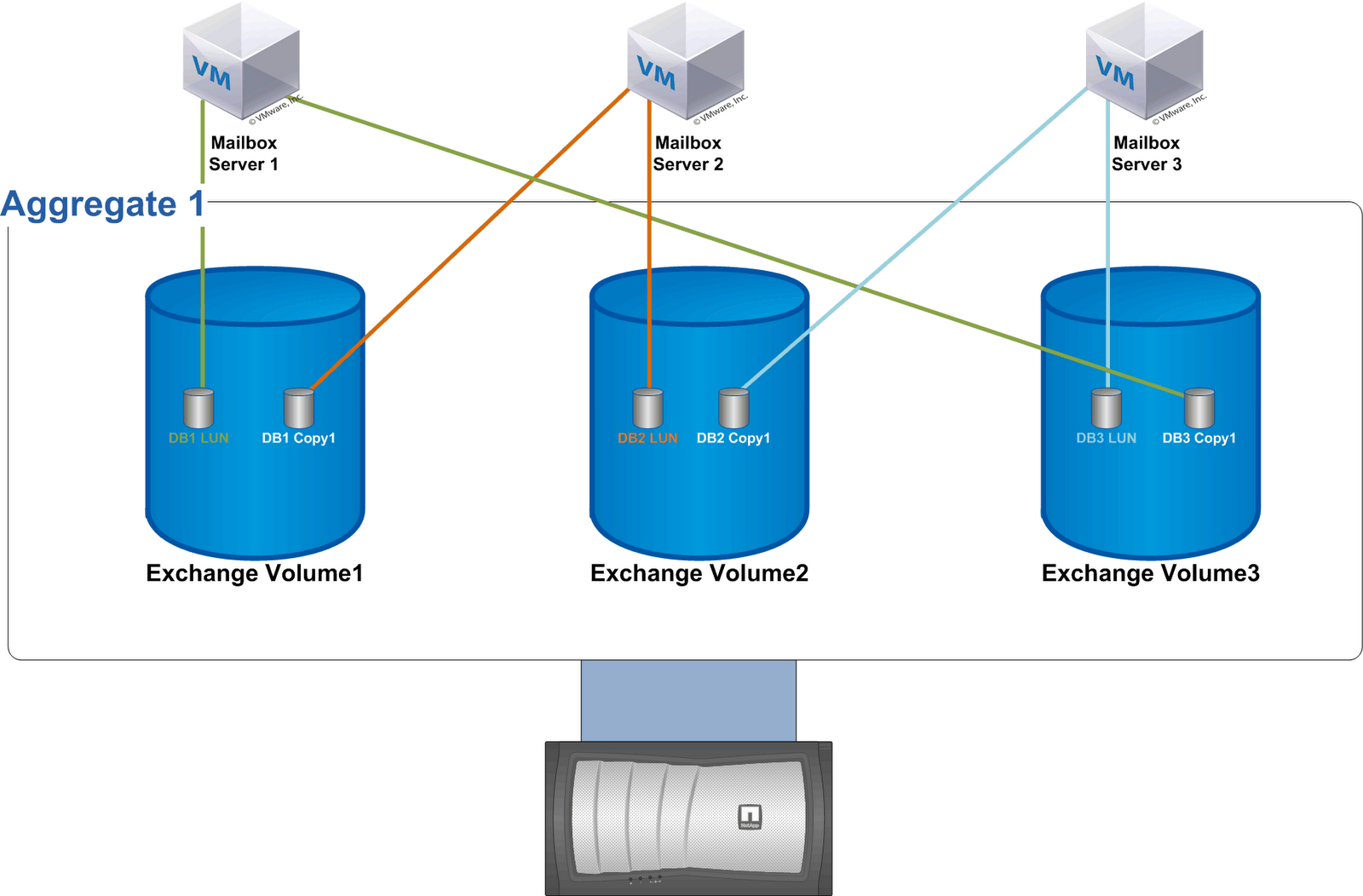
Exchange 2010 introduced the database availability group (DAG), which enables you to design a mailbox resiliency configuration that is essentially a redundant array of independent Mailbox servers. Multiple copies of each mailbox database are distributed across these servers to enable mailboxes to remain available during one or more server or database outages.
As part of your design process, you need to design a balanced database copy layout, which may in turn, require you to revisit several design decisions to derive the optimal design. The following design principles should be used when planning the database copy layout:
Design Principle 1: Ensure that you minimize multiple database copy failures of a given mailbox database by isolating each copy from one another and placing them in different failure domains. A failure domain is a component or set of components that comprise a portion of the overall solution architecture (e.g., a server rack, a storage array, a router, etc.). For example, you would not want to place more than one database of a given mailbox database within the same server rack, or host it on the same storage array. If you lose the rack or the array, you end up losing multiple copies of the same database (perhaps your only copies!).
Design Principle 2: Distribute the database copies across the DAG members in a consistent and efficient fashion to ensure that the active mailbox databases are evenly distributed after a failure. The sum of the Activation Preference values of each database copy on each DAG member should be equal or close to equal, as this configuration will result in an approximately equal distribution of active copies throughout the DAG after a failure (assuming replication is healthy and up-to-date).
In order to follow these design principles, we recommend you place the database copies in a particular arrangement to ensure that the active copies are symmetrically distributed across as many servers as possible. This arrangement of database copies is based on a “building block” concept.
1. The first building block (known as the Level 1 Building Block) is based on the number of mailbox servers that will host active database copies. Assume this number is N. N defines not only the number of Mailbox servers, but also the number of databases within the building block. One active database copy is distributed on each server forming a diagonal pattern represented on the diagram below.
For example, let’s say we have 4 servers, each with its own dedicated storage and deployed in a separate server rack, and we want to deploy 24 databases with 3 copies of each database. In this case, the size of our first level 1 building block is 4 and looks like this (copy layout is highlighted in yellow):

The same pattern is then repeated for each remaining level 1 building block set (given 24 databases, there are six Level 1 Building Block sets in this example).

2. As you add second database copies, you place them differently for each building block set. Since one server is already hosting the active copy, there are N-1 servers available to host the second database copy. As you use each of these N-1 servers once, you have a complete symmetric distribution which will form the new larger building block. Therefore the new building block (known as the Level 2 Building Block) size becomes N*(N-1) databases. This means that the second database copy for the first database is placed on the second server, and each second copy thereafter is deployed in a diagonal pattern within the building block. After the pattern is completed within the first Level 1 Building Block set, the starting position of the second copy for the next block is offset by one so that the second copy starts on the third server.
In our example, the building block size now becomes 4*(4-1) = 4*3 = 12, which means that 12 databases make up each Level 2 Building Block set. Note that for the Level 1 Building Block set 1 (DB1-DB4), the second copy for DB1 is placed on Server 2, while for the Level 1 Building Block set 2 (DB5-DB8), the second copy for DB5 is placed on Server 3. Each Level 1 Building Block set starting server for placement is offset from the previous one by one server. This layout is continued by placing the second copy for DB9 on server 4. This ensures that a server 1 failure will activate second copies across all three remaining servers rather than activating multiple databases on the same server, which provides a balanced activation.

This pattern is then repeated for each remaining Level 2 Building Block set (given 24 databases, there are two Level 2 Building Block sets in this example). Note that the second copy for DB13 is placed on Server 2.

To understand this logic better, compare database copy placement for databases 1, 5, and 9. All of these databases have the active copy hosted on server 1, so if this server fails, you want to have second database copies activated on different remaining servers to achieve equal load distribution. This is what you achieve by placing second database copy of DB1 on server 2, second database copy of DB5 on server 3, and second database copy of DB9 on server 4. Starting with DB13, you simply repeat the pattern.
The rest of the database copies are added in a diagonal pattern (bolded):

3. As you add a third database copy, again you need to place it differently for each group of now N*(N-1) databases. Since now you have only N-2 servers available to choose from for the third database copy placement, this generates N-2 variations, such that the new building block (known as the Level 3 Building Block) becomes N*(N-1)*(N-2) databases. Therefore, the third database copy for the first database is placed on the third server, and each third copy thereafter is deployed in a diagonal pattern according to that starting position within this new building block. After the pattern is completed within the first Level 1 Building Block set, the starting position is offset by one so that the third copy is placed in the fourth position.
In this example, our building block now becomes 4*(4-1)*(4-2) = 4*3*2 = 24, which means that 24 databases make up each Level 3 Building Block set. To produce the symmetric database placement pattern, place the third database copy of DB1 on Server 3 (this is the first available server because Server 1 hosts the first copy and Server 2 hosts the second copy), and offset each next copy by 1 until you reach the end of the Level 1 Building Block set 1. For the next building block set, again place the third database copy on the next available server (Server 4), and continue in the same manner until you reach DB12 which marks the end of the Level 2 Building Block set 1. For databases 13-20, follow the same pattern but offset third database copy placement by 1 so that it doesn’t end up on the same servers as for databases 1-12.

Again, to understand this logic better, compare database copy placement for databases 1 and 13. These databases have the active database copy hosted on server 1, and the second database copy hosted on server 2. If both servers fail, you want to have the third database copies activated on different remaining servers to achieve equal load distribution. This is what you achieve by placing the third database copy of DB1 on server 3, and the third database copy of DB13 on server 4. Similar “pairs” are formed by databases 2 and 14, 3 and 15, and so on. Starting with DB25, you would simply repeat the pattern, but this example does not have that many databases.

4. As you add a fourth database copy, again you need to place it differently for each group of now N*(N-1)*(N-2) databases, such that the new building block becomes N*(N-1)*(N-2)*(N-3) databases. This follows the same logical approach and ensures that the database distribution will be even within the new building block in case of 3 server failures.
The example of 4 servers leaves only 1 variation for placing the 4th database copy (as there is only one remaining server available), so the building block size actually remains to be 24. This is also seen from the formula for building block size, as 4*3*2*(4-3) = 4*3*2*1 = 24.
5. As you continue adding more database copies, the building block keeps growing such that the general formula for the building block size is Perm(N,M) = N(N-1)…(N-M+1) = N!/(N-M)! = CNMM! (where N=number of servers and M=number of database copies). This becomes obvious as you realize that complete symmetric distribution of the database copies is achieved by selecting all possible permutations of M database copies across N available servers.
In the event of a single server failure (server 4, for example), the active mailbox databases will be distributed as follows (the second copy is activated for databases 4, 8, 12, 16, and 20, denoted in dark orange), which results in no more than 8 activated mailbox databases per server (assuming replication is healthy and up-to-date).

In the event of a double server failure (the third copy is activated for several databases and denoted in green), the remaining two servers, Server 2 and Server 3, will have an equal number of activated mailbox databases (assuming replication is healthy and up-to-date).

Conclusion
Hopefully this guidance helps you with planning your database copy layout. If you have any questions, please let us know.